SemDynReg: Semantic-Guided Deformation Regularization for Dynamic 3D Gaussian Splatting
Abstract
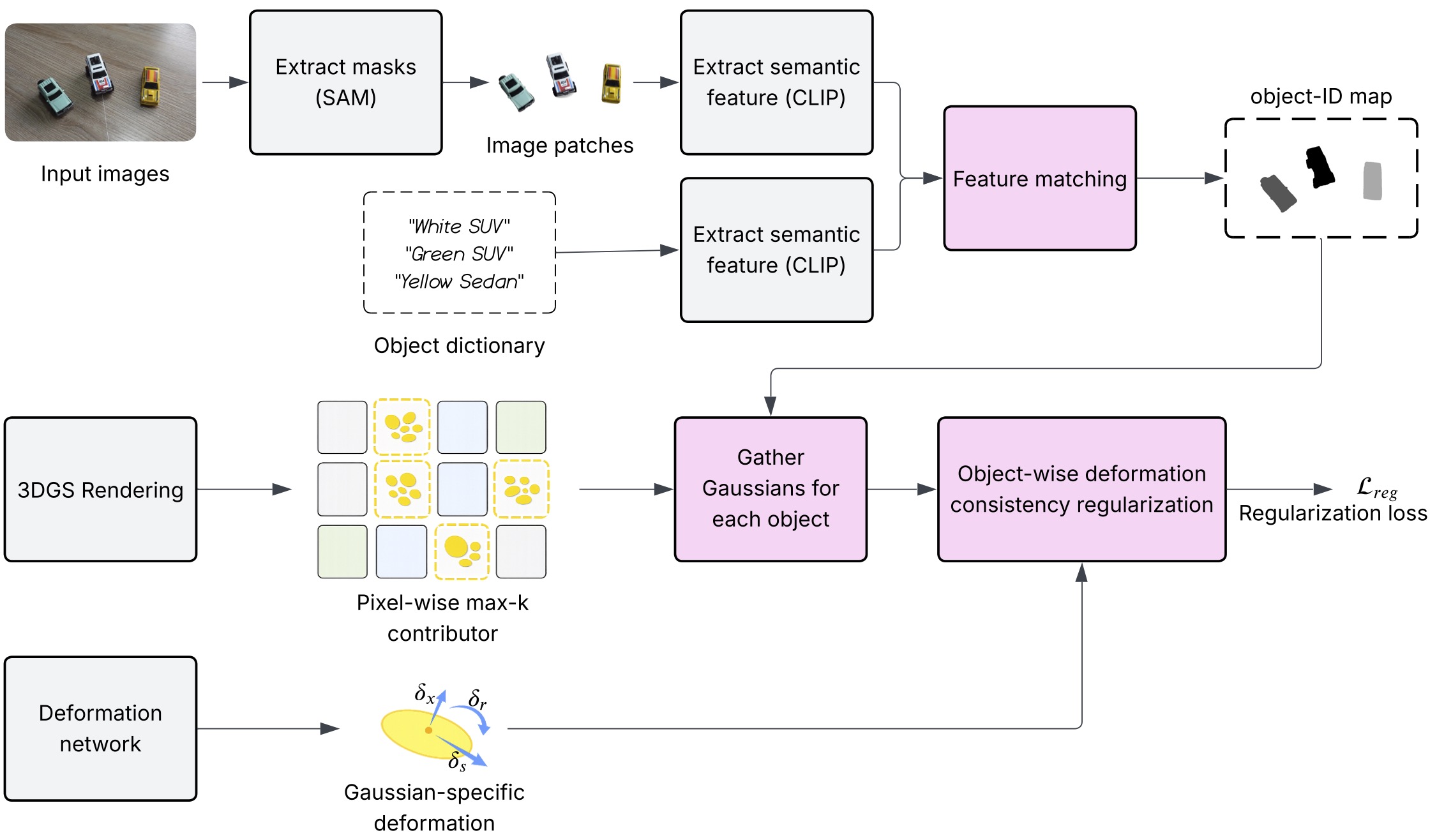
Abstract: Deformable 3D Gaussian Splatting (3DGS) enables efficient rendering of dynamic scenes, supporting a wide range of emerging 3D applications. However, existing deformation field–based approaches largely lack explicit object-level modeling, often resulting in inconsistent Gaussian deformations within individual objects and across different objects. To address this limitation, we introduce a semantics-guided framework that enforces dynamic regularization at the object level, aiming to achieve spatially consistent object-wise deformation. Specifically, we first extract segmentation masks using the Segment Anything Model (SAM) and derive semantic features from input images. An object-ID map is then constructed via feature relevance matching with a predefined object dictionary. Guided by this object-ID map, we identify the pixel-wise top-𝑘 contributing Gaussians for each object and impose consistency regularization on their deformation parameters, including position, scale, and rotation. Unlike prior methods that learn deformation fields without explicit object-level constraints, our approach incorporates semantic cues to guide deformation behavior at the object level. Experimental results demonstrate that this semantics-aware regularization significantly improves object-level consistency in dynamic 3DGS rendering.
Overview of Our Pipeline
Demo
Scene Description
We present experimental results across three separate scenes, each containing three cars, including one moving vehicle and two static ones. The cars serve as the primary objects of interest. To distinguish them, we use semantic prompts—“White SUV”, “Green SUV”, and “Yellow sedan”—and match them with extracted semantic features to obtain object identities. The moving car is identified based on the deformation magnitude (scale) of its associated Gaussians. We then apply object-level regularization to enforce more consistent deformation among the Gaussians belonging to that object.
For each scene, we provide comparisons between the Ground Truth and the Rendered Scene with dynamic regularization applied. In addition, we train a semantic feature field that enables feature-based rendering, as shown in the Rendered Feature videos, where the three cars are represented by distinct gray levels. These learned features are further used for object identification and motion extraction, as illustrated in the Segmented Rendering and Dynamic Object Rendering videos.
Dynamic Scene 1
Ground Truth
Rendered Scene
Rendered Feature
Segmented Rendering
Dynamic Object Rendering
Dynamic Scene 2
Ground Truth
Rendered Scene
Rendered Feature
Segmented Rendering
Dynamic Object Rendering
Dynamic Scene 3
Ground Truth
Rendered Scene
Rendered Feature
Segmented Rendering
Dynamic Object Rendering
BibTeX
@article{YourPaperKey2026,
title={SemDynReg: Semantic-Guided Deformation Regularization for Dynamic 3D Gaussian Splatting},
author={Ruitao Chen and Jinge Li and Mozhang Guo},
journal={Conference/Journal Name},
year={2026},
url={https://your-domain.com/your-project-page}
}